
You're Kidding Right?
No, but I am not referring to the calculations themselves, just the process by which we do it.I went off down this track in the year 2000 as a 23 year old. I was working on an adaptive load balancer for a very large blue-chip insurance firm who refused to give me and my team decent hardware. OK, that's a bit harsh. The project was temporary in nature, but existed for a very political reason. To get it out of the door quickly, we had to make do with disparate hardware, so I wrote a special load balancer which adapted to the load that came in by keeping a tally of connections and adapting to the mean of the latency of the heterogeneous [mongrel] server specs we were given. It would also judge the computing agent's performance and so would route traffic to the most appropriate node given it's average performance over it's lifetime and the number of connections it currently had. It was called MAALBA (Mean Average Adaptive Load Balancing Algorithm - So very geek!).
Believe it or not, the principle of an average could have become a huge headache!
No, You Really ARE Kidding Right?
Nopety. Let me explain why.
Look at the equation below, which calculates the average latency of a system i the standard way.

Where Li is the latency and L 'bar' is the average latency.
There are/were two things wrong with this standard average calculation in the load balancing context.
Linear Increase in Calculation Time as the System Aged
A standard average requires the sum of all samples. Each time a new entry comes in, the whole sequence had to be calculated again. This meant that as the system doubled in age, the time take to calculate the latency also doubled.
If you have 10 items in your list, this is just 9 CPU additions and a division. 10 ops in total, no big deal at all. However, now make this 1 million items and suddenly you are running 1 million operations just to calculate an average! This would also have to happen at speed, for each and every single one request. This massively affects the performance of the load balancer and hence it's ability to route traffic to nodes in the network.
However, this particular problem could be solved quite easily by simply keeping the running total in a variable store which was then updated as each sample came in. Great!
Summing all Latencies Leads to Overflow
As we know, numerical types in systems have a maximum number they can store. This is usually a function of the word length. So an unsigned 32-bit system can store a maximum of 4,294,967,295. No surprise there. However, the latency of a system was in milliseconds and there would be multiple-millions of samples going through the computing array every day. So you could get to the maximum size of the integer in a very short lifetime. You could choose to use floats or doubles, but they would be equally problematic and keeping a running total would be no use in this regard, in that this is exactly the problem it causes.
See my point?
Yes, So? Solution?
The thing with average equations, or indeed any equations which have an inductive form, is that you can convert it into what maths bods call a 'recurrence relation'. This is a relationships which uses the previous value as the baseline for the new calculation.
This is particularly easy to exemplify. For example, the curve of compound interest can be represented by:
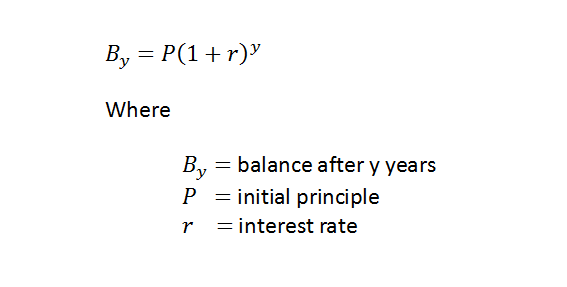
Or, you can represent this through a recurrence relation by storing the previous balance, which is what Banks (and you) do and multiply this by the interest for this year.

For those astute with language, functional programming or maths, you'll notice that a recurrence relation has a continue condition, which calls an equation of itself and also an initial condition (or rather, terminal in this case) which stops the recursion when it reaches year zero. This is simply a recursive function. So the recursion calculates as it unwraps from year zero.
So Use Recursion?
No! Absolutely not! The problem with using recursion for the average equation is you still risk an overflow. Not just that, but you also risk a stack overflow because running a series of 1 million recursive calls stores 1 million stack frames on your stack, which may be 20 to 40MB or more, which for a 32-bit stack is huge! Multiply this with the parallel number of requests and the threads used and you have gigabyte of memory in use, on an OS which could only address 2GB at best, 200 MB of which is used by the OS itself. I those days, this would have killed a huge server!
No, you couldn't just use recursion. The trick is to know that unlike compound interest, which are divergent in nature (the curve never flattens out. It gets steeper) averages regress to the mean. This is a convergent process, which eventually flattens out nicely. Given that the maximum you could ever have for a latency would be the maximum value of the integer type chosen, unlike compound interest, you could never overflow! After all, if all your samples were 4,294,967,295, then dividing this by the number of samples would give you an average of 4,294,967,295. If latency was anywhere near this, we'd consider this a hung process anyway!
OK, OK What Does it Look Like?
Solving the average calculation required me to transform the average equation into a recurrence relation and then store the previous average in memory.
To create the recurrence relation, I actually expanded the equation to release the terms necessary for the previous average:

Which then became:

The terms in the square brackets are the previous average! So we can complete this algebra by substituting the term for the previous average and we end up with:

And to reduce by one more calculation, finally:

What this means is that for any new average latency calculation, all you need do is take the previous value and perform 4 calculations on it, whatever the size of the history! This means there is no linear increase in latency to calculate the average before routing.
OK, Having Talked the Talk...
That's the theory. So how much faster does this go?
I lost the results a long time ago, but I'll be rewriting this in code and posting it on one of my GitHub repos. The following table compares the normal .NET average against this new average calculation for extra-small (10), small (100), medium (1,000), large (10,000) and extra-large (100,000) numbers of samples, of numbers between 1 and 1,000, 1 and 3,600,000. To simulate the latency of up to an hour in each of these, request cases, we have to compare with an agent which calculates the average the traditional way for each request.
The code for the calculation of the average from the maths above is simply:

So nothing special. The test for this spike simply ran the average and compared it to the value .NET gets through the .Average() aggregate method and sure enough:

You can see where the Resharper for VS2013 icon shows the test went green. So we're calculating the right value.
Next I ran the configuration described above and the results are shown below (in milliseconds). The Latency Ratio is just the performance of the recurrent average against .NET's average calculator:

The tests were run on a logarithmic scale. Plotting these as graphs show us how the different algorithms performed as the size of the lists got bigger.
 |
| 0 to 1s samples, .NET average v recurrent |
 |
| 0 to 1 hr samples, .NET average v recurrent |
As the system hit 100,000 items in the list, the standard average calculation failed to perform to even 1% of the speed of the recurrent algorithm.
Conclusion
As you can see from the above results, the .NET average calculations performed really poorly in the tests compared to the recurrent version of the code. So you could be forgiven for thinking I am about to tell you to ditch the .NET version.
Far from it! The only reason this worked is because of the fact we needed to accumulate an understanding of the system which converged to a value, in this case the average, and the prior 'knowledge' the system had didn't change. If we could go back and change the numbers of historical effects, we would be stuck with a system which could only use the standard average calculation and nothing more! Since we'd have to reprocess the samples and the history each time.
This just goes to show that an awareness of the context of an algorithm is a really importance factor in high performance systems. Unfortunately, it's one of the things you can't refactor to alone. Refactoring may given you the ability to pick out the old average calculation method to then replace with this, but not develop the algorithm for a new one such as this, especially from scratch. Anyone beating on anyone else for 'analysis paralysis' should hopefully be hanging their heads in shame at this point.
What I would like to do is illustrate the effect in multi-threaded environments. This will really show how the system performs in both sync and asych environments, as this has a direct bearing on the scalability of systems. One day I'll get round to rewriting that one :-)
0 comments:
Post a Comment
Whadda ya say?