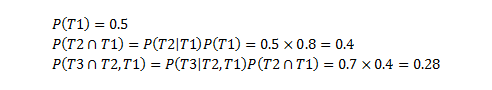It's 8am here in the UK and I am still simmering over a twitter storm from about 3am my time. I made the mistake of looking at my phone after going to the bathroom (I washed my hands) and noticed more on the #NoEstimates conversation.
It all centred around the heated discussion the other day on #NoEstimates, except this time it got personal, with a few members of the discussion choosing to do the tabloid headline thing of taking one part of some of my material out of context and then basically making libellous inferences. I don't mind a heated debate at all, as long as it stays fair, but I was somewhat disgusted with the
actions of a few
folk, especially since they purport to work with probability and statistics, which folk who know me well, know is exactly my area of specialism in this domain. If you want to read the full article on my LinkedIn blog post and see how it's out of context, it's
here, as opposed to reading the tabloid rubbish. They obviously TLDR or were out for the vendetta as opposed to admit where they were wrong. Too much riding on it I guess.
Needless to say, twitter is a really poor forum for these sorts of discussion (which is pretty much the only thing me and @WoodyZuill agree on). So I figured I'd explain it here, in a bit more detail, then post it back, as those folk are hell bent on not admitting their lack of understanding and fighting with people on 'their side' of the debate and to do that, needs a lot more than 140 characters to explain the gaps. However, before we get into how they fit within the discussion of estimates, we need to bridge some gaps and answer some criticisms.
Buzzwords
Now, I hate 'buzzwords' as much as the next guy. However, we in IT are probably more guilty of creating and using them than any other industry. Indeed, particular communities of practise create buzzwords that only those in those communities understand. Therefore it is a kind of 'private joke'. However, here's the rub, you can't get away from it. They are always necessary to succinctly communicate a concept. 'eXtreme programming', 'design patterns', 'TDD', 'Refactor' they are all examples of words used to communicate concepts in our domain. They mean nothing outside it to anyone not connected to it. So those people see it as a 'buzzword'. Is that their problem or ours?
Similarly, because we in software development are often in no way connected to accountancy and finance, when see words like 'NPV', 'IRR', 'ROR' we in the main don't get an illustration of the concepts in our minds. Hence, we see them as buzzwords. Their problem or ours?
 |
| The moment of violent agreement |
So, hopefully we should now be on the same page around 'buzzwords'. Cool?
No? Do we not like hearing that?
Grow up!
Estimates (or None)
When working in an organisation, you're always going to have to justify your work's existence (sometimes even your salary/fee). It's how businesses work. Why are we doing this project? What is the business case? How much is it going to cost? What benefit am I getting out of it? The answers to all these questions are all estimates. Yes, we hate them because we are often held to them. However, being held to them is a people problem, not a problem with estimates. Business are held to estimates all the time!
Estimate Risk
Estimates are naturally probabilistic. What is worse is that the further out you look, more uncertain that probability becomes. To expand on a previous
post from the past, using insignificant data volume as an example, if you imaging you have to deliver one small task and you estimate it to take 2 days and it takes 3 days, you have one data point, with one variation of 1-day (or 50% of it's expected duration - average absolute variation of 1-day). If you then get another task and you estimate it to be the same size and it takes 1-day, then you have a range of total variation of -1 day (delivered early) to +1 day (delivered late) which is 2 days in total. You can't make a decision on one data point.
The
average absolute deviation, which is is the average across the two, is 2/2 = 1-day. That's just standard statistics. Nothing special there. You can relate that to standard deviation really easily (sum of the residual differences) and this comes out as the square root of 2, since the mean of 3 days and 1 day is 2 and the variance is 2-days. Standard deviation is the square root of variance, ergo...
Now, let's suppose you classically estimate ten such elements (deliberately staying away from 'story' as to me, a story is an end-to-end, stand alone piece, so shouldn't have a classical dependency per se) in a dependency chain on a critical path and you don't improve your process to attain consistency, the total absolute variation goes from all of the tasks being delivered early, to all of them being delivered late. From the mean (2 x 10 = 20), this becomes a range of -10-days (1 day early for each task) to +10-days (1 day late for each task) a total absolute deviation for the whole project of 20-days on a 20-day expectation, even though the individual tasks still have an average total deviation of 1-day!
Let's now imagine we're actually delivered stuff and look at the variation of the tasks remaining after these first 2 tasks on the board have been delivered and their variation was as stated previously. Those are now not uncertain. They have been delivered. There is no future uncertainty about those tasks and of course, no need to further estimate them. The only variation now exists for the remaining 8 tasks on the board. Again, 1-day average absolute variation, means the 8 tasks remaining now have a total systemic (i.e. whole project) variation of -8 to +8 days (16-days). So you can see the variation reduce as you deliver stuff.
It's reduction makes that darn cone to look like it does! Since you're now 4 days into the project. You can plot that on a graph.The first point of uncertainty was +10 and -10 on day zero. 4 days in, this has reduces to +8 and -8. You keep going across the time on the x-axis as you deliver stuff and you
always get it finishing on a final point. After all, once you have delivered everything, you have no more variation to contend with. Zero, zilch, nada!
 |
| example of a cone of uncertainty (src. wikipedia) |
There is no getting away from this fact. It's as much of a fact as the law of gravity. To do anything that goes against it without understanding it, is like
this. Which whilst fun and harmless (some might consider 'pioneering'), killed people when flight was first invented and in any case, spends money pointlessly, which is waste. We are in a position where we know better, why reinvent the wheel?
What does this have to do with Estimates?
Right, here is where we get back to the meat of the matter. 'How do estimates help me deliver better software'.
In short, as far as software development alone is concerned, it doesn't. However, and this is the bit that ired me because people just didn't seem to want to hear it, software development by itself, is useless. We use software to solve problems. Without the problem, there is no need for software (indeed, there is no need for any solution). However, don't forget organisations themselves solve client problems and those clients themselves solve problems potentially for other clients! So software development doesn't exist in isolation. If you think it does, then you exist in the very silo mentality that you purport to want to break down. Do you not see the hypocrisy in this? I am sure many of the business readers do!
Again, grow up!
Teams Should Aim to use the closeness of their estimate and actual delivery performance as an informal internal indicator of the level of understanding of the codebase and their performance with it. No more. Businesses should not use the estimate to hold the team to account as there is a high level of variance around any numbers and the bigger the system being built, especially if it has a number of components in a chain, the worse the variance will be.
Improving?
The way to improve on estimates totally depends on the way the team itself works. Let's assume the team carried out retrospectives. This is their chance to employ practises to improve the way they work, quality of the work and/or pace at which they develop software. As a rule, the team can't go faster than it can go, but the quality of the code and the alignment of the team naturally affects the flow of tasks carried through to 'done' (production, live, whatever).
Blockers and bugs naturally affect the flow of work through the team. Reducing them, improves the flow of work, as contention for the 'story time' of the team, which is a constrained resource, then isn't there. If you don't track bugs/blockers, then you are likely losing time (and money, if you're not working for free) as well as losing out on opportunity costs or potential income (probabilistic) in value for the business be delaying deployment into done and you'll have no idea if that applies or not. If it does, the business is getting hit on two fronts.
- Delivering value later because you are fixing bugs in earlier processes
- Costing more money to deliver a feature because you are using 'story time' to fix bugs in earlier releases
The combination of the effects of the first and the second hits your
NPV and hence, directly affects your
IRR and also
ROR and
ROI (buzzword alert). However, most developers are too far away from finance to understand this and many who purport to understand it, don't.
How can methods like Kanban and ToC help?
OK, so it's no secret the IT world, the one I inhabit, has an extremely poor understanding of flow and indeed, does kanban 'wrong' relative to the real way lean happens in manufacturing and TPS. Kanban ultimately aims to optimise flow of X. Flow of stories, tickets, manufacturing items, cars, whatever.
 |
| My scribbles on importance of understanding variance from previous posts |
The process is stochastic in nature, so there is no certainty around it but what most folk don't understand is that kanban inherently has naturally got waste in the process. Movement of items is one of the recognized 7 types of Muda waste
- Unnecessary transport and handling of goods
- Unnecessary motion of employees
Transportation of goods (read stories) is a movement of one item from one stage, to another. Often a development context to a QA one or into live. There is a change of 'mental model' at that point, from one mindset, say, development, to another, say QA. That is a form of context switch, just not using time, which shouldn't be new (after all, context switching happens with stack frames on CPUs when multi-threading - Take out and store the stack frame for one thread, introduce the frame of another) and just like all context switching, it never costs nothing to do.
In addition, as per
ToC (buzzword alert), there is inventory, and indeed, a 'wait time' between stages where the item is ready to be pulled on demand can be considered an implied 'inventory' stage. This introduces another cost. Usually in not delivering the software into a production environment so it starts to yield knowledge or indeed, it's value.
Run a dojo and try this. Take one developer and make them code and QA one scenario. Time how long it takes to deploy that one thing into a production environment. Then take another developer and a tester and make them code one scenario and then QA that one scenarios in sequence. Time how long it takes. You'll never get faster with the QA and the dev. The cost to switch the task naturally elongates the
cycle-time of the software delivery of that one task. If you did 10 tasks like this in an iteration, all sequential and the dev didn't pick up another one until the QA signed it off for live, then the throughput would be just 10 x the cycle time.
In short, introducing a kanban stage has introduced waste! You'd lose time/money as a business.
What's the benefit for this cost? What's the trade-off?
To answer @PeterKretzman's retort
 |
| Still think so now it's been explained? |
The systemic trade-off is pipelining tasks to make team delivery faster ( to be delivered by the team). Each stage can pick up a 'ready' task from the previous stage when they've finished their main involvement in their stage/phase of the story's flow through the pipeline.
Run the same experiment with 10 scenarios and this time the dev can pick up a task whilst the QA is testing the previous one. Suddenly this makes much more sense and your throughput, whilst still related to cycle-time, is not wholly dependent on it. So you are delivering the 10 scenarios much faster than you would do if it was sequential. After all CPUs use pipelining as a standard optimisation mechanism. This is obviously why we do what we do in the way that we do it in software, lean manufacturing, lean construction or anything else.
Can you get too small?
As I demonstrated in a talk I gave last year, the short answer is yes. If you keep adding columns to the point it doesn't add value i.e. isn't a step in the
value chain (buzzword alert) then all you are introducing is the cost of the context switch out of that stage, with no value add, which then costs both time and money. Indeed, if you can run tasks wholly in parallel pipelines, it's much faster than kanban, but requires resources to be allocated accordingly.
To see this in the previous example, introduce a post-QA stage called 'stage' and all they do is sign a pieces of paper and then run a manual deployment. There is no value add in that process, since there are no other contentions for the 'stage' process in the organisation as it is at that moment in time. However, you're paying a post-QA personnel member money to stage it.
Conclusion
I hope folk can now see where I am coming from. However, make no mistake, I am extremely disappointed in the quality of understanding around this, the hypocrisy that exists in the field and the low down, dirty tabloid style tricks that some folk will stoop to just because they've never come across such a scenario, and as if they know it all from all organisations everywhere. The #NoEstimates movement is sadly littered with such folk who frankly seem to show a distinct lack of understanding of anything related to the field. Many show a distinct unwillingness to engage, inherently overly political standpoints to avoid having to admit a failing, limited success or understanding. After all, the only people who'd want to sell #NoEstimates if it doesn't mean anything are the #NoEstimates movement. It's a real shame as it's something I think needs to be discussed with a wider audience and as I have said previously, it has massive potential, but is being taken down a black hole with pointless discussion and constant justification across the board.
After all, if we can't constantly be responsibly critical of our field, our means of operation, then we can never ever improve what we do?
E