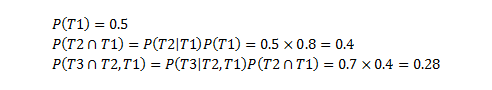Shared services came about because it's easy to segment such business functions into individual cost centres, potentially even into single accounts within a company's CoA (aka charts of accounts) which do make things much easier to report on. They also seem to have evolved functions at board level, such as CFO, CIO and CTO.
In recent years, it has become clear that this is a somewhat wasteful idea for a number of reasons and in the reporting sphere, not least because the end of month, quarter and annual reports and management accounts occur so infrequently relative to the lines of business operating all the time. However, there is an even bigger problem with this and it is the level of complexity this introduces into the organisation's operating model which happens to also mean that any operational task spanning multiple shared services contends for its time, is more complex to manage, passes through several chains of responsibility and due to the contention, generally takes longer to pass through the operating chain. For this intro, I will skip a significant portion of the maths, but the whole process of illustrative relevance is based around queuing theory.
Modern methods which aim to make organisations more responsive, such as Lean Start-up or agile software development, have inadvertently stumbled onto the answer. The reason they address this pain point so well is they amalgamate functions of all the various shared service centres into one, self-sufficient team. This type of organisational unit makes it really easy to manoeuvre in the space, shortens the time through the queue (aka the cycle-time) and inherently reduces complexity. Today I'll work through an example of the problem and compare this model to the newer, more agile cross-functional teams.
Traditional Hierarchy
In a traditional shared services hierarchy, you may have a chief operating officer who is responsible for the operations of the enterprise, which will include operational services, call centre management and such like. A CTO or CIO who has responsibility to deliver IT shared services. Some companies have CMOs, of course, CFOs exist etc. What is often correlated with that board structure is a hierarchy of specialisms. So an accounts division or department, a marketing division or department, an information systems division or department.
The interesting thing is that managers who have been through typical managerial courses, especially at MBA level, will have drawn up 'value chains'. These chains start with a raw material, and refine it into an end product. Alternatively, they begin with a customer entry into the system and travel through a series of steps, services or stages through the organisation before coming out at the other end, healthier, wealthier and wiser.
Consider the following organisation:
Let's suppose this represents ACME plc. That wonderful road-runner extermination device provider. Coyote is getting old and needs ACME, who he has bought products from for decades, to come in and do the extermination for him. For this, there are a number of processes at work.
The interesting thing is that managers who have been through typical managerial courses, especially at MBA level, will have drawn up 'value chains'. These chains start with a raw material, and refine it into an end product. Alternatively, they begin with a customer entry into the system and travel through a series of steps, services or stages through the organisation before coming out at the other end, healthier, wealthier and wiser.
Consider the following organisation:
 |
| Typical organogram |
Let's suppose this represents ACME plc. That wonderful road-runner extermination device provider. Coyote is getting old and needs ACME, who he has bought products from for decades, to come in and do the extermination for him. For this, there are a number of processes at work.
- Coyote, an existing customer, contacts the Customer Services department
- They are put through to sales and purchases a consultation with an engineer.
- The Sales adviser finds Coyote's details in the system and created a sales entry for an engineer visit.
- Through communications:
- Engineering gets a request which waits in a queue until an engineer is assigned.
- Legal prepare a new agreement for the extra work and send it out
- Engineering schedule their work and assign an engineer to come out, but not before conducting a quick risk assessment.
- A notification message is returned to a CSA to notify Mr/Ms Coyote (could you tell?) that they should expect a visit in some 8 hour window on a day some time from today.
- An engineer arrives at Coyote and does whatever business they do.
- The engineer finishes the consultation and registers the completion of the job.
- ...Which triggers a journal entry in Accounts, incrementing the bill which in turn formalises the contract. This waits in respective queues until officers from each department get to them.
- At the end of the month:
- Accounts run a report for the board on the sales which include Coyote's new order and...
- Marketing Analysts determine the performance of the previous month's sales v costs and effort and adjust for the next month. This is reported to the board and...
- Marketing prepare a press release to tell the world they helped Coyote finally catch roadrunner.
- Credit control raise invoices for all purchases, including Coyote's.
 |
| ACME activities in Coyote's Value Chain |
What's wrong with that?
...I hear you ask. Well, if every department reacts as soon as they get the notification, absolutely nothing. However, in reality, this never happens! Different types of tasks contend for personnel's time. Crucially, because it's a shared service, Coyote is not the only customer that each shared service in ACME has, nor is Coyote's request the only type of request that a department processes (it's the nature of shared services after all).
ACME, having branched out, now have clients including Family Guy Peter Griffin, Chief Wiggum from The Simpsons and Roger Rabbit all wanting different things from the sales people or customer services, maybe calling up customer services to get in contact with tech support etc.
So let's add some numbers to that workload. The arrows represent how long it takes one [red] item to flow in and then out of each subsystem. Effectively, for tech guys, this is your departmental 'cycle-time' and is the difference between the arrival time and the service time. The red dots, where highest priority is reserved for the item on the top right, denote all the work there is and X is Coyote's task which passes into each department at that position in the work queue.
 |
| Aggregate workload |
In each subsystem, counting each dot from highest priority to Coyote's cross (inclusive) and multiplying it by the time in each corresponding arrow, we get the time that Coyote has to wait. Doing this for all subsystems to the point at which Coyote gets a bill, marketing get an idea of whether their latest marketing campaign has worked, the board get a view of how sales of the consultancy service are doing etc. is:
 |
| Total flow of Coyote's new sale |
Note that due to the request being able to come in at any time in the month and us using the very best case of the final day before the reporting run, that is an absolute minimum of 201.75 hours! 201.75 hours! At best over 25 days! That is a minimum of 25 days (and maximum of 55) before marketing can get an understanding of whether or not their campaign worked; the data showing up on the financial reports; the PR exercise coming through (potentially allowing your competition to get in before you with something more interesting for your customers); and before an understanding of your company position can be made! Not to mention crucially, that's 25 working days for your customer to get through this business process! If your cool off period is 14 days, what do you think this leaves them with? The road-runner is certainly long gone!
Working More Effectively
The key to being agile is responding to change and hence knowing faster, working faster and hence reacting to your market when you know you need to change. To 'know it' you need to be able to sample the effect on your market of a campaign and your customer's journey is crucial in this respect.In this scenario, think about switching capabilities from horizontal structures built around the technical services your company provide to each other department, to a fully aligned business process with one member of each of the departments concerned in one, single, cohesive team. The work is also aligned so that it doesn't go out of order. This time the team consists of all members of operational staff and they focus on each case as it comes in, aside from the engineers, who have to take 2 days to schedule and work on their tasks in bulk, as they are out on the road. Let's assume that we remove 50% of the types of task that each department member deals with, so they focus only on this service. The reduction naturally means that they address needs that come in more frequently, using only one type of process, which naturally reduces context switching. To keep things simple, we'll assume a zero-cost context switch for this demo and we can imagine the saving not context switching gives. It will just add to the benefit.
There is always a way to improve. However, a first transition may yield:
 |
| New flow arrangement |
Conducting the same analysis on the above yields.
 |
| Newer, aligned processes |
WOW! What happened?
That's a bit of a difference eh? Now ACME can see the effects of a marketing change on Coyote (or anyone else) in less than a week! The removal of invoicing from the month-end shared service process also both shortens the cycle-time AND reduces variance! Imagine that? The ability as a CEO or COO to know how your organisation is doing and you will not be more than 1 week out of date and be pretty certain of the result! This compares to more than 5 weeks to up to 9 weeks in the previous example. That means you can assess your market standing in less time and know when to change with a high level of certainty. It also means you don't spend so much of your revenue if a process doesn't work. Given the fixed costs of ACME's wage bill and overheads, it would be paying 5 weeks worth to find out what you could have done in less than a week! That means at worst, you are 5 times more efficient and being aligned to the appropriate value chain, shifting 5 times as much traffic through ACME's system translates to being around 5 times more effective! Thinking about this as a factor in the Rate-of-Return of an investment and suddenly this looks very good indeed!Summary
The process above shows the difference that the use of multidisciplinary teams and systems can have on your business process. I've left out some of the complex details, such as task variance and hence system variability.Make no mistake, moving to a more agile business architecture is a culture shift, requiring a significant change in mind-set. Most organisations and indeed managers have spent a lot of time being told that shared services are the way to go and most staff assume hierarchies are the norm. After all, we get 'promoted' and gain higher salaries for higher positions. Hence, changing that will require small, careful, iterative change management, aligning services that already have some overlap with (and hence sympathy for) other services is the path of least resistance and the best road to travel. Take care to run those for a little while and see how it copes. Address issues as they arise and see where the system constraint moves to next (a la Theory of Constraints).
Whilst I am certainly can't advocate the removal of shared services where they are already aligned with the value chain, customer experience or workflow, I do caution that you look out for 'shared services' that appear to be essential to the operational flow, as these are the ones that need to be carefully reshaped. Happy reorganising!