In my last contract at a digital agency, I was having a discussion with a chap I worked with. He's good at TDD and we were discussing why we write tests.
The benefits of testing at developer level are well known. Writing them first and cleanly, amongst other things, provides:
- An acceptance framework containing specifications to develop software against, using success criteria.
- An ability to continually, reliably and consistently test against the same test case
- Provides developer 'documentation', in turn providing an understanding of how the system is supposed to work.
- Confidence that what you changed hasn't borked anything
- When combined with automated test and reporting frameworks, they give fast feedback and a degree of progress reporting.
One thing that came up was that we shouldn't refactor tests. I am personally dead against this idea, since this introduces extra work to change the spec if the functionality need changing. The give-away is over 100% test path coverage. That means you WILL be editing more tests than you should do, which is just wasted time and effort. Note though, if it's a choice of 150% tests or 90% tests, I would choose 150% every time.
However, one thing that wasn't brought up, which I personally think is equally important, especially if the project is high value, high risk or highly sensitivity, is governance.
Ewww... Management speak.
Yes, basically it is.
We have to remember that being agile involves being multi-skilled. Part of that is managing risk and whilst tests give you some degree of that, the test coverage gives you the governance of the code and development that you need. If you have 10% coverage in your project, people have not been doing TDD now have they?
Self-sufficient agile development teams are able to govern the development of the system. Some might think governance is used because you don't trust the developers, but really, it's just as much about managing the risks with the code and gaining the biggest bang for the developer buck (effort). As a team of developers, in order to become self-sufficient, we have to be able to govern the development of the software and by proxy, the team.
QAs and BAs have a pivotal role in this process. They know the real business value in the system and as such, they can guide where to put the testing effort. Developers can also get a sense of the importance of the code because they'll have touched specific code more than once.
Cyclomatic complexity can also be key to all this, since the greater the cyclomatic complexity, the greater the number of tests required. If the cyclomatic complexity is high, the number of tests is high simply because of the combinatorial nature of the tests required to cover this cyclomatic complexity metric.
For example, we are human beings and we are not faultless. Anyone who claims otherwise is deluded. So if you have a piece of code which is touched by several developers, or even the same developers multiple times, it is more likely to contain bugs over time than a piece of code written the same way once and not touched since. The purpose of the tests, amongst other things, is to make sure you don't break anything when the next person touches it or you next touch it. It gives you the confidence to refactor it too. Without automated tests, and the quick feedback it brings, refactoring becomes a nightmare. After all, logical bugs don't go through the automated test sections of the covered code, they fall through the holes where the code isn't (whether due to the lack of acceptance criteria or missed path coverage).
Q: Isn't cyclomatic complexity useless?
Nope. I do often wonder why people say that. The explanations I keep seeing or hearing show they actually understand none of it. You also get criticism from developers that QAs insist on a metric such as cyclmatic complexity less than 10 and we end up coding too much 'crap'. However, let's look at why we have it.
Let's use a variation of the one shown on the MSDN website. This code is deliberately rubbish, without full statement coverage but could still be created using TDD (characterisation tests first) and before refactoring anything.
Using FxCop, dotCover and the Code Analysis Powertools in VS2010, you can analyse the solution and get the following:
 |
| dotCover statement coverage and the FxCop equivalent code metrics. |
The key metric we're focussing on is the cyclomatic complexity (CC) of the method named 'Method'. This is high for the method, but what does this actually mean?
Well, the path test coverage on this would require the developer to write a test for each of those cyclomatic paths through the system. In this case, 15 of them. Filling in the rest as proof:
 |
| dotCover and FxCop analysis of code |
Now, the interesting thing is we have 16 tests for a cyclomatic complexity of 16. Let's understand what this means:
- There are only 10 lines of code in one method, and we have had to write 16 test for it - In itself, not a problem
- We can see some clear areas for refactoring. Again, a good thing (see below as I go through it)
However, let's compare this with a wrapper if statement (which tests for whether you care or not), then we can see we have to change more code than we otherwise would have to and this costs the business more.
I've refactored it to use a surrounding 'if' wrapper. The tests still pass, but the cyclomatic complexity has reduced to 9.
 |
| dotCOver and FxCop analysis after refactor |
However, we still have 15 tests. So our coverage now sits at about 167%. That is 67 percentage points more code that another developer (or even ourselves) would have to change if we needed to change the class to do something. This is also only one level of nesting. Adding this method to another method as full, which is covered 166% means the total combinatorial effect means we have 276% coverage. If the combined TDD development time of a module is 5 days at say, 3:2 dev to test during the TDD iterations, then the tests should only account for about 0.72 of a day and development taking the same amount of time (3 days), the other 1.28 days is just sheer waste. That's 26% of the development time.
Scale this (best case) to each time a block of code changes and suddenly, if the code is changed 10 times across stories in an iteration, you suddenly have 12.8 days that just disappeared out of a 50 day project! That's a lot of effort, time and money wasted. Development teams should respect the people that trust them to deliver, who also pay their wages.
The following is the NUnit TestFixture:
using NUnit.Framework;
namespace WhatCanIDo.Test
{
[TestFixture]
public class DayOfTheWeekTest
{
[Test]
public void WhenItsMondayAndYouCareThenSayItsMonday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Monday, true), Is.EqualTo("Today is Monday!"));
}
[Test]
public void WhenItsMondayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Monday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsTuesdayAndYouCareThenSayItsTuesday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Tuesday, true), Is.EqualTo("Today is Tuesday!"));
}
[Test]
public void WhenItsTuesdayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Tuesday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsWednesdayAndYouCareThenSayItsWednesday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Wednesday, true), Is.EqualTo("Today is Wednesday!"));
}
[Test]
public void WhenItsWednesdayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Wednesday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsThursdayAndYouCareThenSayItsThursday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Thursday, true), Is.EqualTo("Today is Thursday!"));
}
[Test]
public void WhenItsThursdayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Thursday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsFridayAndYouCareThenSayItsFriday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Friday, true), Is.EqualTo("Today is Friday!"));
}
[Test]
public void WhenItsFridayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Friday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsSaturdayAndYouCareThenSayItsSaturday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Saturday, true), Is.EqualTo("Today is Saturday!"));
}
[Test]
public void WhenItsSaturdayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Saturday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsSundayAndYouCareThenSayItsSunday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Sunday, true), Is.EqualTo("Today is Sunday!"));
}
[Test]
public void WhenItsSundayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Sunday, false), Is.EqualTo("You don't care!"));
}
[Test]
public void WhenItsDunnoDayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.DunnoDay, false), Is.EqualTo("You don't care!"));
}
}
}
You can see that as we went along, we 'coded' the tests for each of the "don't care what day it is" scenarios right into the code. The excess ones now are not needed at all, since whatever we do, the don't care is actually decided separately from each check on the day. So these can be removed, which will remove 7 test cases.
Important Notes
If you do refactor tests, and I personally think you should, then:
- NEVER refactor tests if the code is red!
- Use the tests to green the code and the code to green the tests but never change both at once!
Removing the 7 extraneous tests then makes the test class look like:
[TestFixture]
public class DayOfTheWeekTest
{
[Test]
public void WhenItsMondayAndYouCareThenSayItsMonday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Monday, true), Is.EqualTo("Today is Monday!"));
}
[Test]
public void WhenItsTuesdayAndYouCareThenSayItsTuesday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Tuesday, true), Is.EqualTo("Today is Tuesday!"));
}
[Test]
public void WhenItsWednesdayAndYouCareThenSayItsWednesday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Wednesday, true), Is.EqualTo("Today is Wednesday!"));
}
[Test]
public void WhenItsThursdayAndYouCareThenSayItsThursday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Thursday, true), Is.EqualTo("Today is Thursday!"));
}
[Test]
public void WhenItsFridayAndYouCareThenSayItsFriday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Friday, true), Is.EqualTo("Today is Friday!"));
}
[Test]
public void WhenItsSaturdayAndYouCareThenSayItsSaturday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Saturday, true), Is.EqualTo("Today is Saturday!"));
}
[Test]
public void WhenItsSundayAndYouCareThenSayItsSunday()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.Sunday, true), Is.EqualTo("Today is Sunday!"));
}
[Test]
public void WhenItsDunnoDayAndIDontCareThenSayYouDontCare()
{
Assert.That(DayOfWeekConverter.Method(DayOfWeek.DunnoDay, false), Is.EqualTo("You don't care!"));
}
}
gives us 8 remaining tests and sure enough:
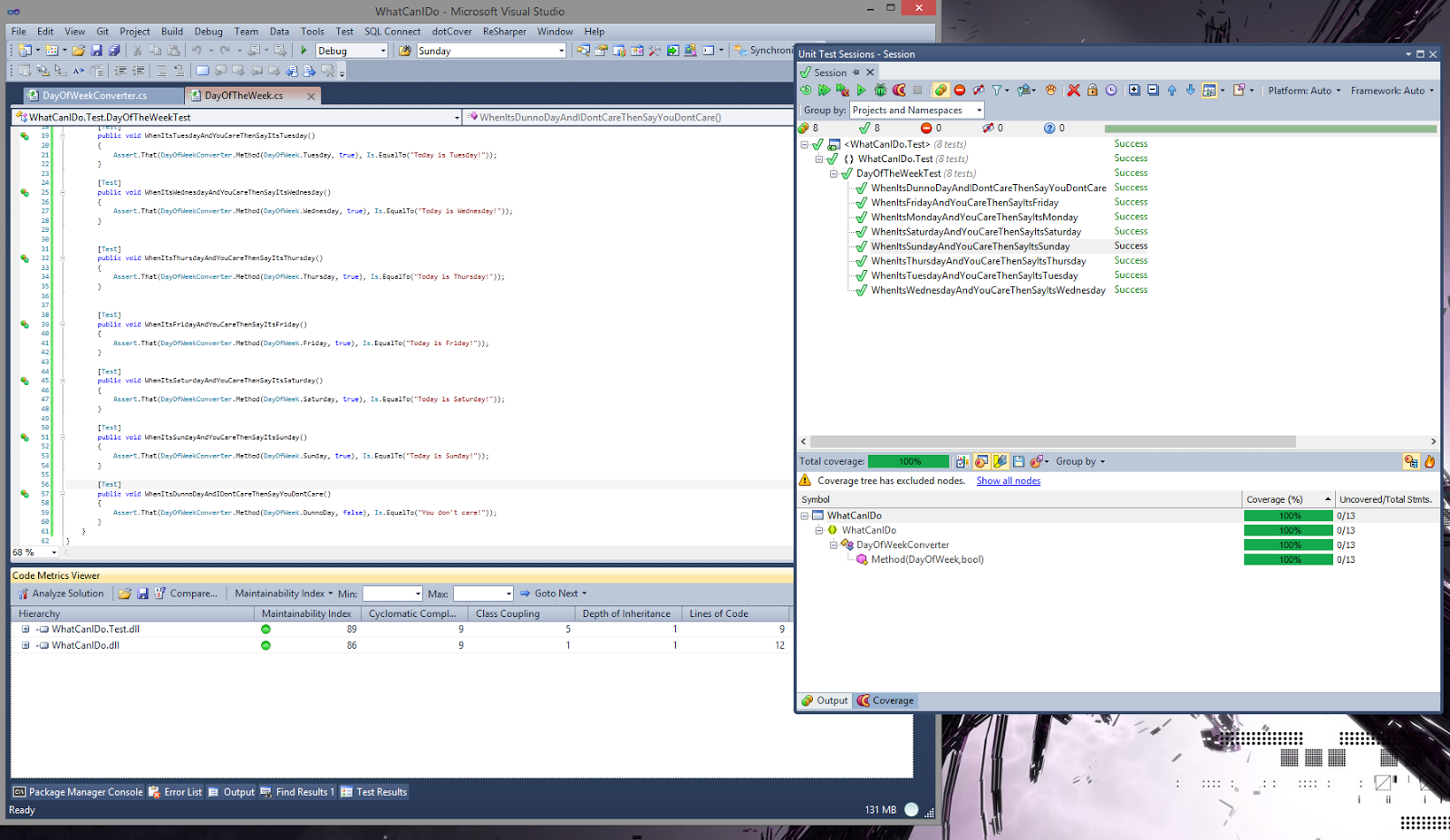 |
| dotCover results after removal of 7 extraneous tests |
Summary
In short, cyclomatic complexity is a brilliant metric for governing how many tests are needed in your solution. There are two main useful comparisons in isolation and teams should take heed:
- If cyclomatic complexity is greater than the number of tests, then you're missing test scenarios and risk introducing bugs into the system. If there is a hole in a bucket, Henry can't carry as much water. Most Agilists should aim to get here as a bare minimum in today's industry.
- If the cyclomatic complexity of a method is less than the number of unit tests around it, then you have over 100% coverage and you introduce waste into your process. This comes when you step agile up to the lean plate!
So to be lean, 100% should be the norm. Anything else is suboptimal or worse.








